
2 month MiniPC mini-review: Minisforum AI X1 Pro
AI Max 395+'s little brother

AMD’s Strix Halo, the AI Max 395+ CPU / APU is the current bang for buck for AI workstations, but at around $2500, systems built with it are still a bit pricey. I got my AI X1 Pro from Minisforum as a replacement (with some additional payment to cover the price difference) when my AI 370 MiniPC died a couple of months ago. Hopefully, this one will last some useful amount of time. It’s basically half the price of an equivalent 395 system.

Compared to the AI 370 model, this one is substantially bigger. It’s no longer a handprint-sized case, but a substantial book-sized block. A big improvement is that this time, most of the case is made from aluminium, which should improve thermals. Judging from the temperatures reported in hardware monitors, temperatures are noticeably better - up to 10-15 degrees C lower than before.
I got the 96 GB RAM model. The RAM is a bit slower then in the old model. Now it’s DDR5 5600, while before it was LPDDR5X 7500, which is reflected in the memory benchmark - AIDA64 reported read speeds in high 60ies GB/s, while before it was in high 80ies GB/s. Memory bandwidth is the single biggest limitation of this APU, and it’s probably why AMD never properly supported it with ROCm.
I’m running Windows on it. The software has evolved a bit and the machine runs LLMs with llama.cpp and Vulkan slightly faster than the old one. On the same model (deepseek-r1-distill-qwen-14b), previously I got inference at around 7.5 tokens/s, while now I get around 8.8 tokens/s.
Here are some llama-bench results on a random assortment of models.
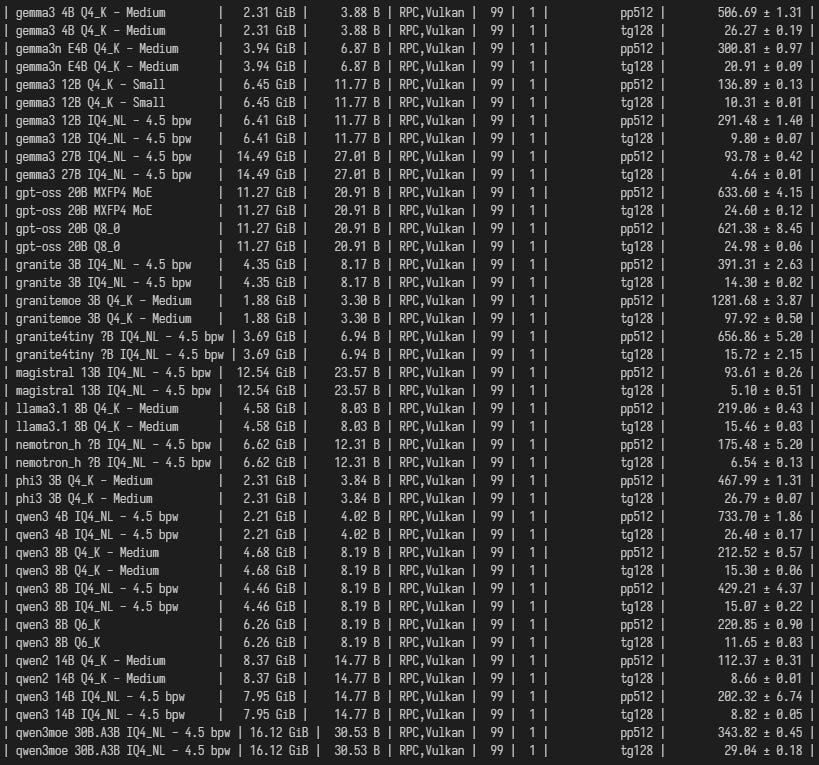
Llama.cpp reports the following version and settings:
load_backend: loaded RPC backend from C:\LLM\llamacpp\ggml-rpc.dll
ggml_vulkan: Found 1 Vulkan devices: ggml_vulkan: 0 = AMD Radeon(TM) 890M Graphics (AMD proprietary driver) | uma: 1 | fp16: 1 | bf16: 1 | warp size: 64 | shared memory: 32768 | int dot: 1 | matrix cores: KHR_coopmat
load_backend: loaded Vulkan backend from C:\LLM\llamacpp\ggml-vulkan.dll
load_backend: loaded CPU backend from C:\LLM\llamacpp\ggml-cpu-icelake.dll build: 6682 (638d3302) with clang version 19.1.5 for x86_64-pc-windows-msvc The CPU is still the AMD Ryzen AI 9 HX 370, with 4 performance cores, 8 efficiency cores, and hyperthreading, which gives us a total of 24 cores. It’s still a super-fast CPU. I find that UMA works pretty well with this APU, so I’ve only assigned 16 GB dedicated to the GPU. Larger models can allocate up to around 40 GB more RAM as needed, without much performance difference. But, since large models run pretty slow, I don’t actually use them normally. 20 B - 30B models with MoE are pretty much the maximum that can be run here with decent speed.
This time, there were no “day 1” problems with BIOS or the AMD drivers, and everything just worked. The system generally works smoothly and cool.
One big addition is that this machine has an Oculink port, which I plan to use later to connect an external GPU, for more serious AI performance.
So, is it worth it? Maybe. Probably. If the 395 model was available when the AI370 died, I would have upgraded to it, but under the circumstances, it’s ok. I would have probably switched to an eGPU anyway.